This article aims to not just explain how DNSSEC work but why the protocols are designed the way that they are. I will begin with a simple mental model of public-key cryptography, then I highlight issues with scheme described so far and add complexity to fix issues as I highlight them. I finish the article with a simplified model of DNSSEC and a range of problems/question that I hope to explore in the next article.
DNSSEC is a collection of IETF specifications for securing DNS data. It is a set of extensions to DNS which provide to DNS resolvers with:
- origin authentication of DNS data
- authenticated denial of existence
- data integrity
It does not provide the DNS resolvers with:
- availability
- confidentiality, DNSSEC results are not encrypted
- protection from user mistakes/assumptions
DNSSEC aims to adds security to DNS, while maintaining backwards compatibility.
RFC 3833
DNSSEC protects DNS resolvers from forged DNS data, by digitally signing all DNSSEC replies. The DNS resolver is then able to check if the information it receives is identical to that information on the authoritative DNS server.
DNSSEC can also protect information such as cryptographic certificates stored in CERT records in DNS.
RFC 4398
RFC 4367
Negative article on DNSSEC
DNSSEC-bis is the name of the DNSSEC specification and the related RFCs are
4033 introduction & requirements, 4034 resource records for DNSSEC and 4035 on protocol modifications.
Public-key cryptography is the use of two keys, one public and one private to encrypt and decrypt a message. A message before encryption is referred to as plain text and a message after encryption is referred to as cipher text.
Public-key cryptography can be used to provide confidentiality or authentication.
To provide confidentiality, the public key is used for encryption so anyone can write a message but only the intended recipient has the private key which is used for decryption, so the only person who can decrypt the message is intended recipient.
To provide origin authentication, the private key is used for encryption so the only person who can send an encrypted message is the intended source. Then the public key is used for decryption so anyone can read the message, provided it was written by the intended source.
 |
| Figure 1 – How public key cryptography can be used to provide authentication or confidentiality |
DNSSEC works by digitally signing the results of DNS look-ups using public-key cryptography. It uses public-key cryptography to provide authentication not confidentiality. This means that private key is used for encryption and the public key is used for decryption. So when a DNS resolver makes a DNSSEC query, then the response will be signed by the correct information source and then the DNS resolver will use the public key to decrypt the response, knowing the response is reliable as it was definitely send by the intended source.
So that’s the problem solved, the DNS responses will be encrypted by correct source and then all the DNS resolvers will decryption the responses using the public key. This ensures that the response was sent by the correct source so it provides source authentication as well an data integrity as it was signed using a private key.
Except that this model completely ignores the details of how DNS actually generates the replies to DNS query and what exactly is the “intended source” in this context.
So now I want to explain why the basic public-key cryptography scheme that I outline is not sufficient to provide authentication.
The cryptography scheme aimed to provide authentication between the DNS resolver and the source of the DNS response, but it didn’t consider the details of how this DNS response was generated.
The actually answer is that the “intended source” in DNS is an Authoritative Name Server, There are many authoritative name server forming a distributed database, each authoritative name server responses to a specific subset of the DNS queries.
The DNS resolver needs to locate the relevant authoritative name server, this is achieved through a chain of domain name servers, either recursively, iteratively or a hybrid of them both.
To generate the response to a DNS query for the DNS resolver, there are a series of request-replies. So for DNSSEC to meet its primary goal of providing authenticated responses, there needs to be authentication throughout the chain between the DNS resolver and the intended source, which is the authoritative name server. When a DNSSEC enabled DNS resolver gets a response then it can use the public key to check that it was encrypted by the authoritative name server.
So now we have fixed the problem … Actually not
This solution would require that all DNS resolvers change because all DNS resolvers need to decrypt the DNSSEC response using the public key to get the the normal DNS response. Given that DNSSEC nees to be backwards compatible with DNS, this means we need to alter the above scheme.
So instead of encrypting and decrypting the whole DNS response, why don’t we add some text to the DNS response as another resource record and then encrypt and decrypt that text instead. This means that DNS resolvers that are not DNSSEC compatible can simply ignore the extra resource records. This extra bit of information therefore acts as a digital signature. This is actually used in DNSSEC and the new resource record is called RRSIG.
Now we have DNS record with an extra resource record called RRSIG, the authoritative name server has the private key and the DNS resolver use the public key to check that the DNS information received was from an authoritative name server. But where do the DNS resolvers get the public key from ?
A simple idea would be to have a single server with all public keys on, then all DNSSEC enabled resolvers could just request the public key from the central server. This is fundamentally flawed as its a centralized system which would completely defeat the purpose of DNS, which is to act as a distributed system.
Therefore we need a distributed system of our own to get the public keys to the DNSSEC enabled resolvers, why not use a system like DNS or even DNSSEC ?
DNSSEC gets the public key, from the authoritative name server to the DNSSEC enabled resolver by introducing another new resource record called DNSKEY. This has the public key in it so that the DNS resolver can use it to verify the RRSIG.
Done ? Nope of course not …
So its easy to assume that we finished here but as we developed the scheme we have actually introduced new issues, for example we have lost any data integrity. Its easy for a 3rd party to intersect a DNS query, change the data in the resources and set it forward to its destination. The DNSSEC enabled resolver would be nun the wiser, as the response to the DNSSEC query is still correctly signed and will have the correct RRSIG.
We can fix they by making the plain text in the RRSIG, a hash of the original message. This means that if the messaged is changed in transit then the DNS resolver will detect it because after decrypting the RRSIG text and hashing the other resource records, the results will no longer be the same because the hash generated from the DNSSEC response will be different to the RRSIG one as the text has been changed.
Lets review where we have got to so far…
DNSSEC uses public-key cryptography to provide authentication and data integrity between authoritative name servers and DNS resolvers. It does this using two new resource records, RRSIG and DNSKEY.
The authoritative name server hashes the RRs and then uses a private key to encode this hash, the result is placed in the RRSIG record and the public key is placed in the DNSKEY record. Then the DNS response moves though a chain of domain name servers to the DNS resolver. If the DNS resolver supports DNSSEC then it will use the public key in the DNSKEY record to decrypt the RRSIG, this will give a hash of the other RRs, the resolver can then hash the other RRs and compare the results.
So what is this public-key cryptography algorithm that DNSSEC uses and whats going to happen if its broken in the future ?
DNSSEC doesn’t use a specific algorithm. Both DNSKEY and RRSIG have a 8 bit number, which corresponds to the algorithm used, details of with values correspond to which algorithms is available here
This scheme has a big problem though…
Consider the following situation, I am an evil 3rd party would wants to return the incorrect DNS respond to a (DNSSEC enable) DNS resolver :
- The (DNSSEC enable) DNS resolver places a DNS request for www.google.com
- I spot this and I want to send a reply to this DNS request that will not be from the authoritative name server, managed by Google
- So I’m going to make my own response and make it appear as its has comes from the authoritative name server
- I create RR with the incorrect information and I then come up with my own public and private key pair, using the private key to encrypt the hash in the RRSIG and then place the public key in the DNSKEY record
- The DNS resolver then decrypts the RRSIG record using the key in the DNSKEY and checks that its a hash of the other RR records
- The DNS resolver believes that the response is from the authoritative name server at google
The problem is the above situation is that although the RRSIG and DNSKEY resource records aim to authenticate the other resource records, there is nothing to prevent a 3rd party changing the RRSIG and the DNSKEY. What we need is a method of authenticating the DNSKEY.
If we assume for a moment that the DNSKEY is authenticated, then a (DNSSEC enable) DNS resolver will be able to detect if the other resource records have been changed. As the decrypted RRSIG will not be a hash of the other resource records. If a evil 3rd party also when tries to also change the RRSIG value, so that the decrypted RRSIG is a hash of the changes made, then they can do this only if they know the private key. But they do not know the private key used and they cannot replace the public/private key pair as we have assumed that the DNSKEY is authenticated
So how can we ensure that the DNSKEY is from the authoritative name server ?
DNSSEC works around this is by signing the DNS replies at each step in the chain of response and reply. So when a domain name server queries another domain name server, not only is the expected result returned but also a flag indicating if that zone used DNSSEC and if it does it includes a hash of the DNSKEY record stored in a record called DS.
So far we have introduced 3 new resource records to DNS:
- RRSIG – a hash of the other RRs that is encrypt using the private key by the authoritative name server
- DNSKEY – the public key associated with the private key used to encrypt the RRSIG, a DNS resolver then using this public key to decypt the RRSIG and check that the plaintext is a hash of the other RRs
- DS – a hash of the DNSKEY used in the zone that the DNS resolver is about to query so that the resolver can check that the response from the next name server query has not had the DNSKEY altered because it can check the DNSKEY received with DS received from the last name server.
This hash is then used when the name server queries the zone, as the DNSKEY returned hashed should match the DS RR from the previous query. If the response doesn’t include a DNSSEC RR or the DNSSEC hashed is not the same as the previously returned DS RR, then the integrity of the data has been comprised.
Example
This diagram attempt to demonstrate how the chain of DS and DNSKEY allows use to assume that the DNSKEY has not been tampered with. In this example, a DNS resolver queries the root DNS name server and its returned with the normal DNS response as well as a DS resource record. This DS RR is a hash of the DNSKEY that will be returned then the next DNS request is made. The DNS resolver then queries a TLD name server, this returns the normal DNS response as well as a DNSKEY and another DS. Now the DNS resolver can check that the response was from the TLD name server by checking that the DS that is recieved prevously from the root DNS name server is a hash of the DNSKEY. The DNS resolver can now contiune as it has the DS, which is a hash of the DNSKEY that should be returned by the next name server
 |
| Figure 2 – DNSSEC chain of trust created using corresponding DS and DNSKEY RRs, this assumes that the response from the root DNS can be trusted |
How does the DNS resolver know that it can trust the result from the root DNS server ?
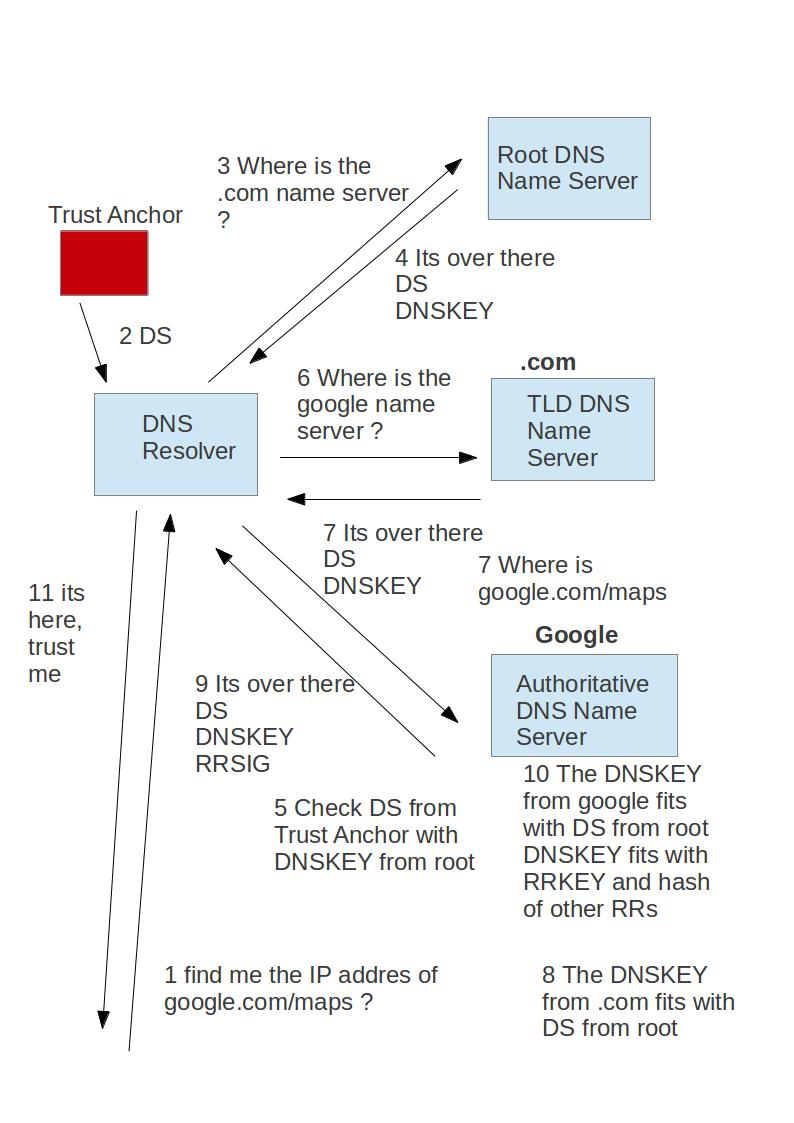
In the above example we cant guarantee that response from the root DNS server is actually from the root DNS server, this is why we introduce a trust anchor
 |
| Figure 3 – chain of trust between a trush anchor and the authoriatative name server using a series of DS and RRSIG resource records |
But this appears just to move the problem, how can we trust the trust anchor ?
We get the DS resource record using a different method where we don’t need to authenticate the origin as we know that the message can’t have been intercepted (i.e. via the operating system)
As you can see we have created a chain of trust using a series of corresponding DS records and DNSKEYs, this means that when we reach the authoriative DNS name server, we know that we can trust the DNSKEY and that is will not have been tampered with.
There is a fun website here, which provides information on the chain of trust.
Thing to consider in the next article:
- What’s the difference between a validating and non-validating stud resolver, which is better ?
- DNSSEC also introduces NSEC and NSEC3 resource records, what are these used for ?
- DNSSEC requires use of the “DO” flag in EDNS, why don’t the DNS resolvers just ignore the RRSIG. DNSKEY and DS resource records ?
- What happens if the authoriative name server do not support DNSSEC, how does the resolver know the difference between DNS response from an authoriative name server that don’t use DNSSEC and a attach where the evil 3rd party tries to pretent the the authoriative name server dose not use DNSSEC
- How exactly goes the trust anchor get the DS for DNS root, what happens if the root DNS needs to update the DNSKEY and therefore the DS record in the trust anchor, if for example the cyptographic algorithm is broken
- How does a authoriative name server prove that an DNS entery don’t exist ?
- In July 2010, the DNSSEC was added to the root DNS, could you use DNSSEC before the root DNS support DNSEC if all other name server and the resolver supported DNSSEC ? DNS Lookaside validation ?
- What happens when a name server between the root and authoriate name server doesnt support DNSSEC but the other name server involved do ?
- Why are there additional timestamps in the RRSIG to limit the time that the signiture is valid ?
- Why are these timestamps absolute not relative like TTLs ?
- How are new keys implemented and what about the caching?
- Whats zome emuation and how can it be dealt with ?