It’s official! Fast Flexible Paxos: Relaxing Quorum Intersection for Fast Paxos, my latest collaboration with Aleksey Charapko and Richard Mortier will appear in next year’s edition of the International Conference on Distributed Computing and Networking (ICDCN). If you don’t want to wait, then the paper is available right now on Arxiv and in the next few paragraphs, I’ll explain why I think this short paper opens the door to some exciting new directions for the future of high-performance state machine replication protocols.
State machine replication
State machine replication (aka SMR) is a widely used technique for building strongly consistent, fault-tolerant services by replicating an application’s state machine across a set of servers and ensuring that each copy of the state machine receives the same sequence of operations. This is the primary responsibility of an SMR protocol such as Paxos, Chubby, Zookeeper[1] or Raft. SMR protocols are often criticized for performing poorly. Typically distributed systems opt for weaker consistency guarantees and reserve state machine replication only for the most critical aspects of a system such as managing metadata, distributed locking or group membership.
Most SMR protocols take a similar approach to deciding the order that operations are applied to the state machines. They elect one server to be a leader and all operations for the state machines are sent first to the leader. The leader decides what order operations will be applied. Before the leader can apply an operation to its state machine, it first replicates it to a majority of servers to back up the operation. The leader can then safely apply the operation to its state machine. If the leader fails, then another server is chosen to become the new leader. A new leader must ensure that it knows about all operations which were applied by the failed leader. Since the previous leader replicated all applied operations to a majority of servers, the next leader can learn of all previously applied operations by communicating with the majority of servers. This is because any two majorities will overlap by at least one server.
In practice, it takes a while for an SMR protocol to apply an operation to the state machine. There are two main issues: firstly, all operations must be sent to the leader and secondly, all operations must then be replicated on a majority of servers.
Fast Paxos
Various SMR protocols have been proposed to overcome the leader bottleneck. Some allow any server to directly replicate operations, without first sending them to the leader. I will refer to this as fast replication. The first protocol to support fast replication was Fast Paxos, which was proposed by Leslie Lamport in 2005.
One downside of fast replication is that when a server replicates an operation, it now needs to make more copies before it is safe to apply the operation. Fast Paxos requires approximately 3/4 of servers to have a copy of an operation before it can be applied [2]. Fast Paxos might have handled one issue, the leader bottleneck, but in doing so, we have made the other issue even worse, we now need around 1/4 more copies of an operation before it can be applied.[3]
Flexible Paxos
Regarding the issue of majority replication, Flexible Paxos showed that leaders could safely replicate operations to fewer servers, provided that more servers were used during leader election. The equation below describes the tradeoff between the number of servers which must participate in replication (R), the number of servers which must participate in leader election (L) and the total number of servers (N).
L + R > N
Since leader election is rare, it benefits performance to reduce the number of servers which must replicate operations (R) at the expense of increasing the number of servers which must participate in leader election (L).
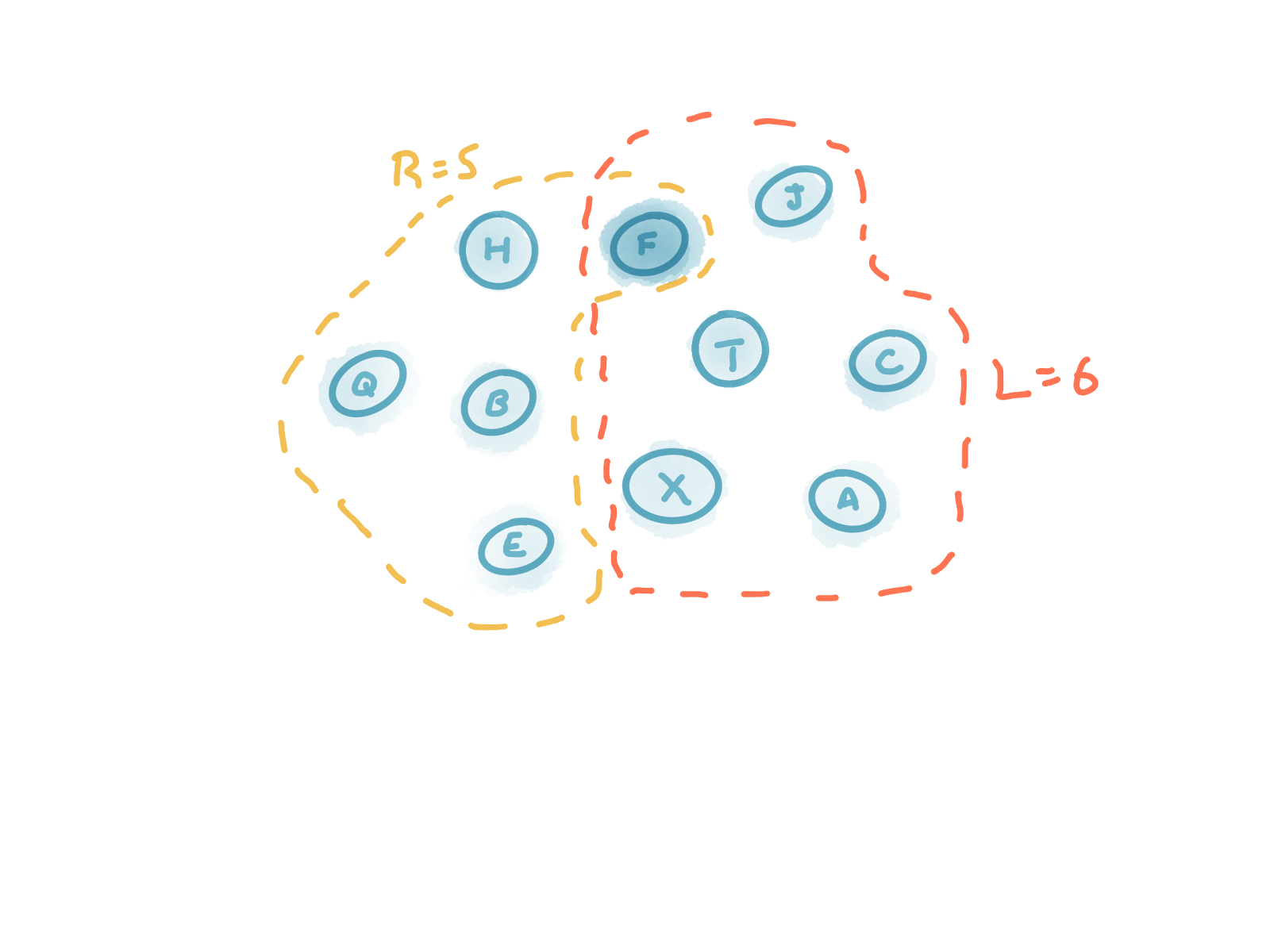
For example, if N=10 then we might use R=5 and L=6.
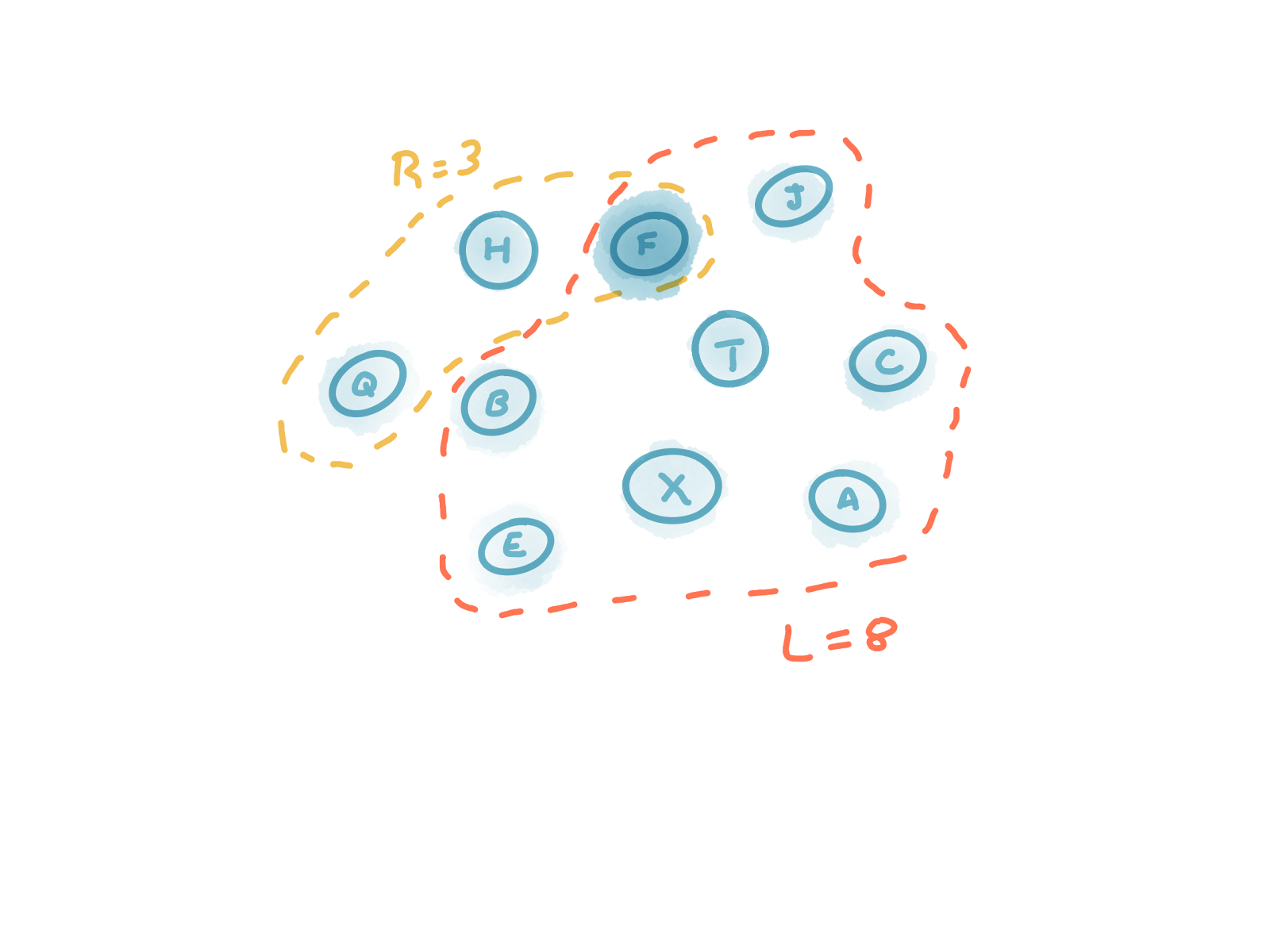
Or we might choose to use R=3 and L=8.
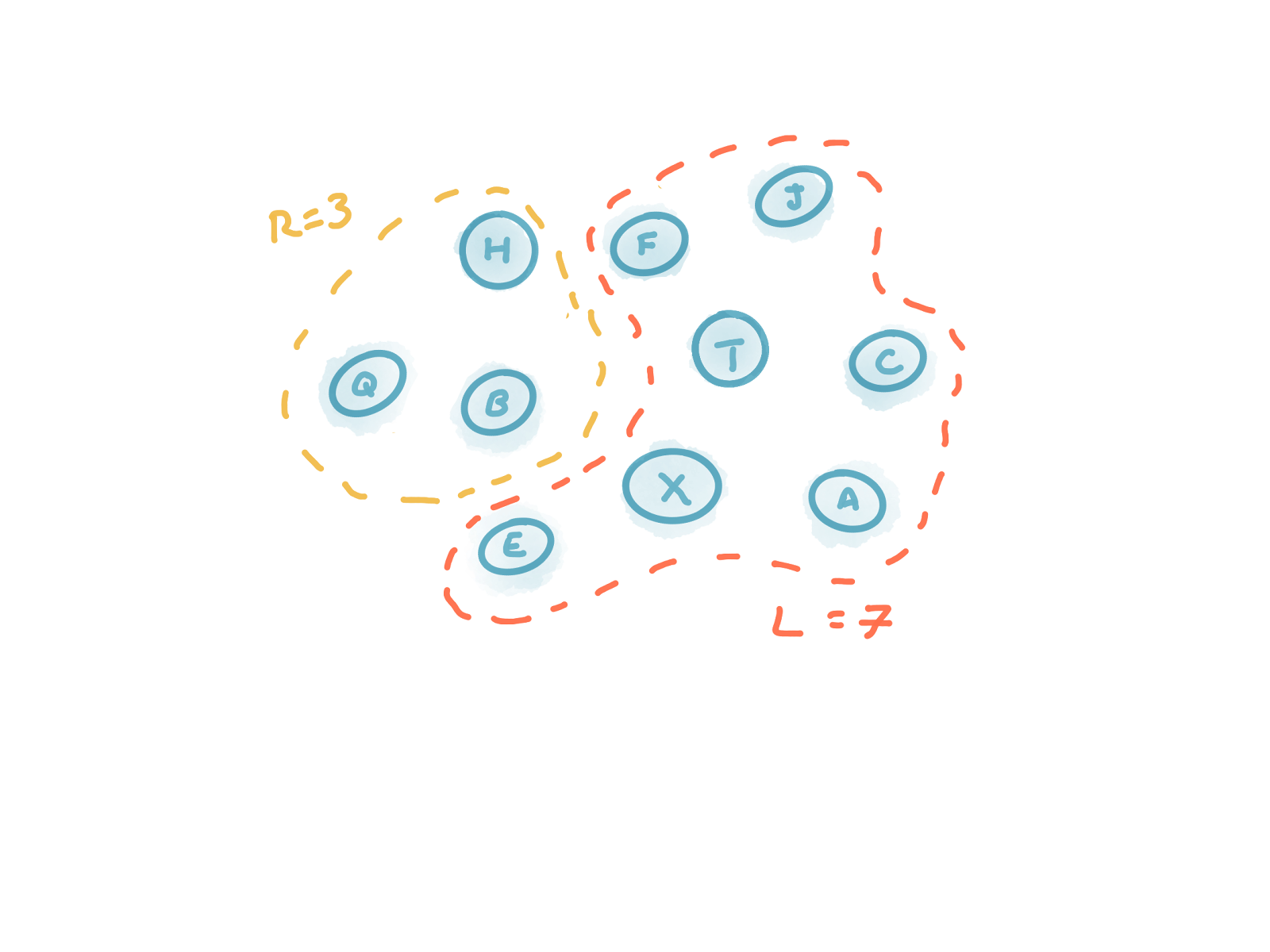
Note that we could not use R=3 and L=7. Our equation ensures that L and R always overlap by at least one server.
Fast Paxos + Flexible Paxos = Fast Flexible Paxos
Unfortunately, Flexible Paxos does not directly apply to Fast Paxos. State machine replication protocols thus need to choose between using a leader and requiring fewer copies of operations (Flexible Paxos) or allowing servers to bypass the leader but requiring more copies of operations (Fast Paxos). In this short paper, we prove that the approach of Flexible Paxos can be applied to Fast Paxos. Fast Paxos can safely replicate operations to fewer servers. We call this Fast Flexible Paxos.
Like Flexible Paxos, Fast Flexible Paxos observes that we can tradeoff the number of servers which replicate operations and participate in leader elections. The equations below describe this tradeoff in terms of R, L, N and the number of servers which must participate in fast replication (F).
L + R > N
L + 2F > 2N
Consider the previous example where N=10, R=5 and L=6, our second equation requires that F=8.
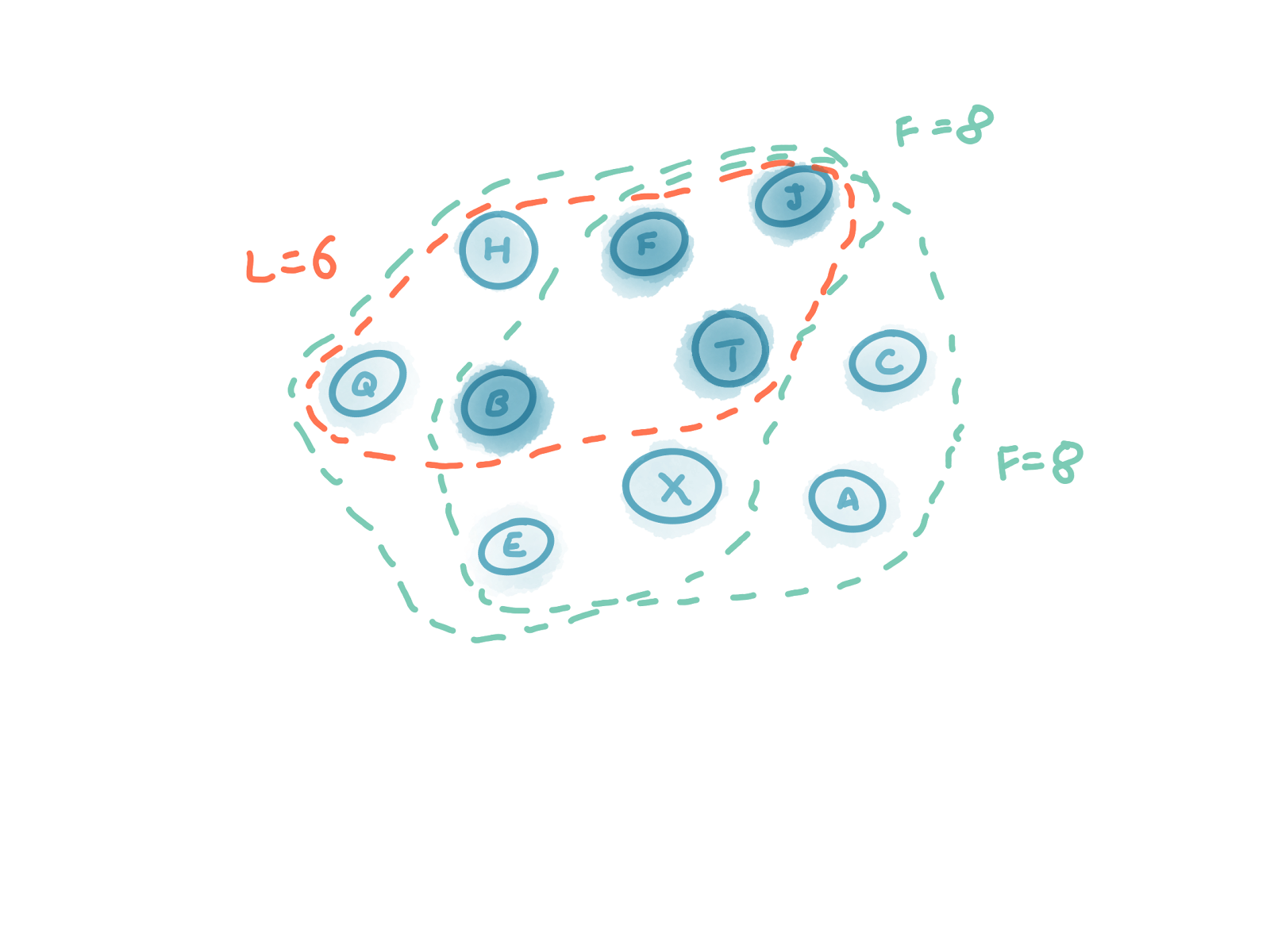
Or consider the example where N=10, R=3 and L=8, this requires that F=7.
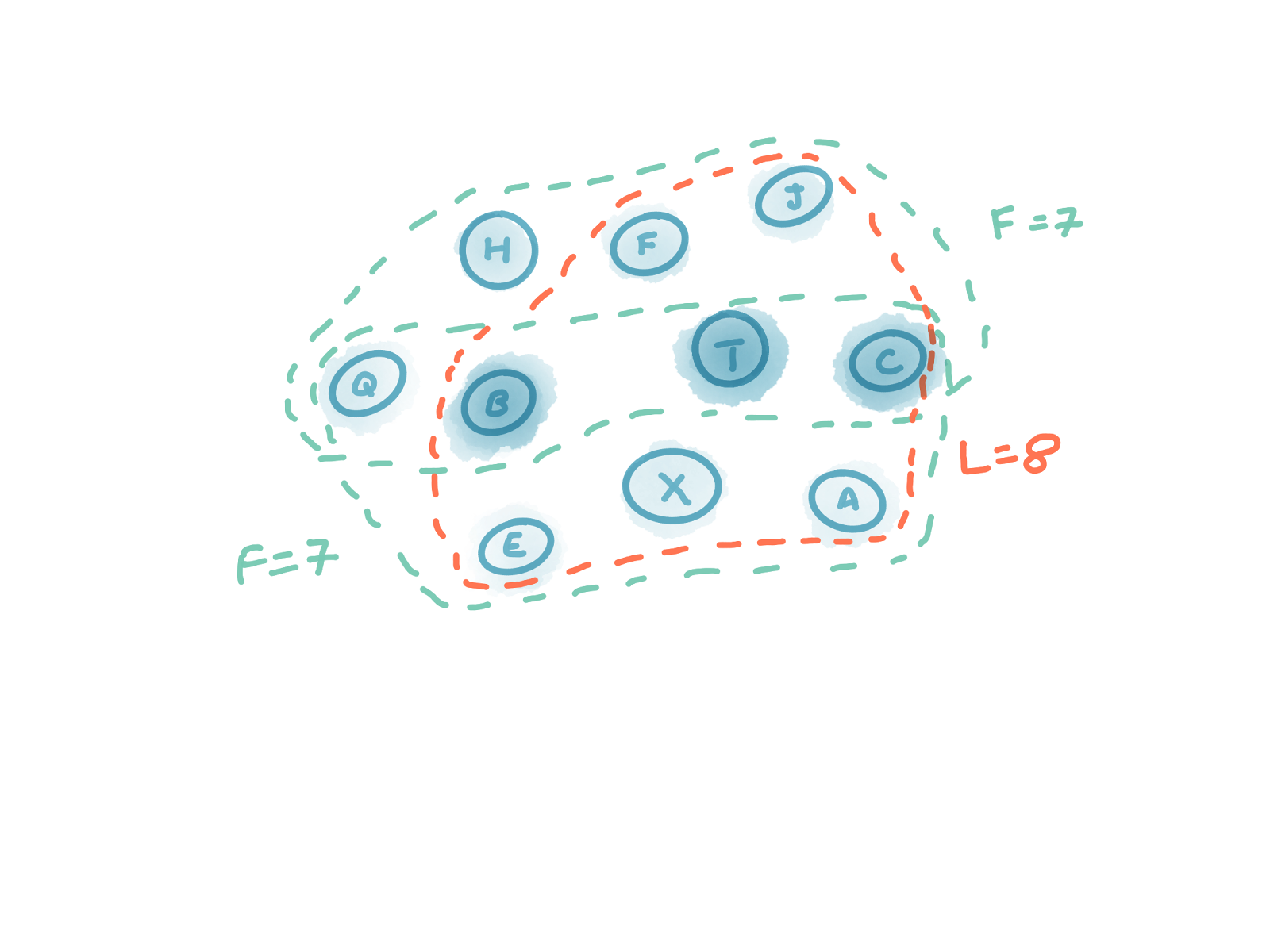
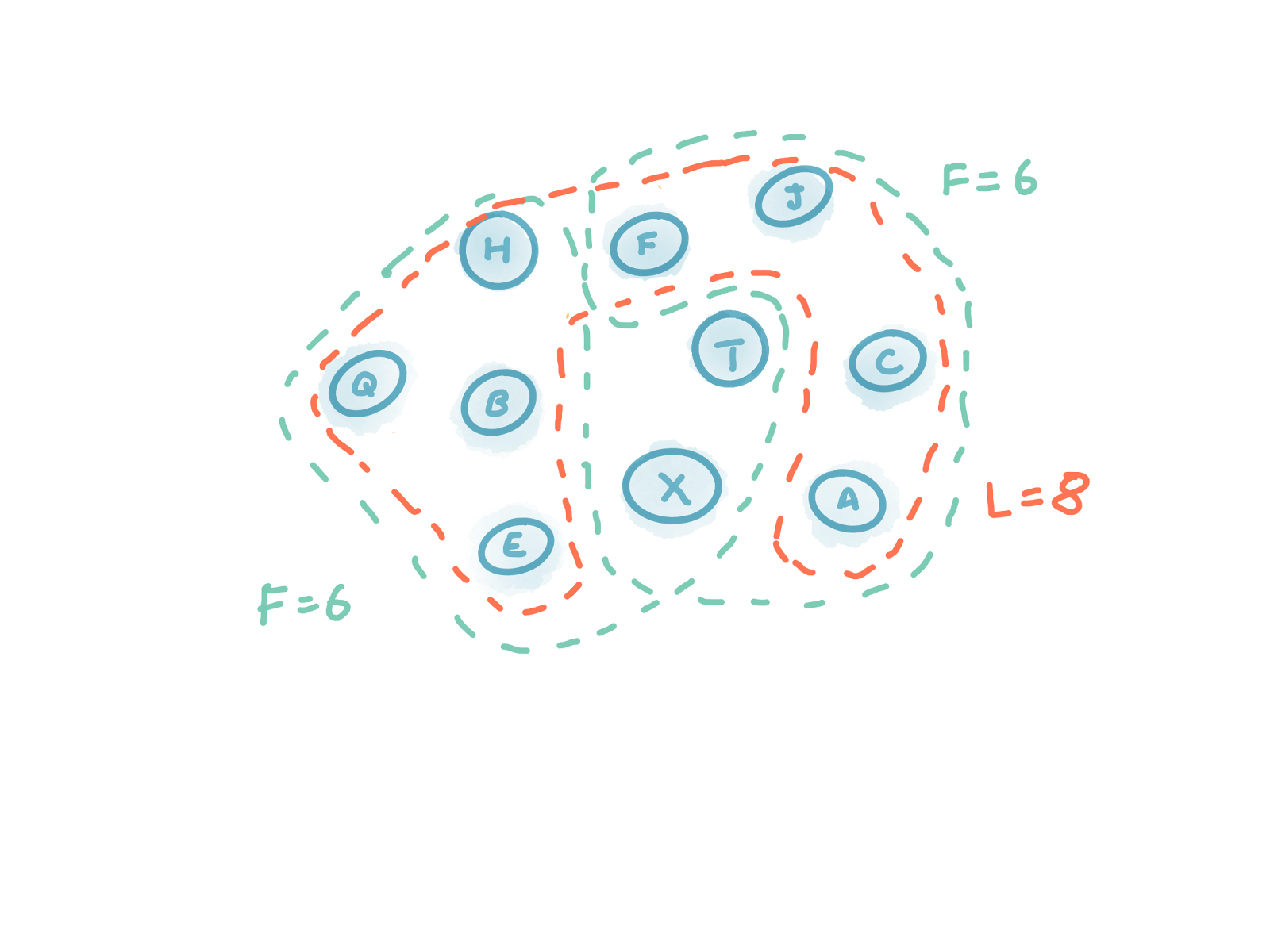
Note that it would not be ok to use N=10, L=8 and F=6, regardless of the value of R, as this does not satisfy our second equation. The second equation ensures that L always overlaps with any pair of Fs, as shown in the diagrams below.
As always with distributed systems, it is a matter of tradeoffs. In the most extreme case, we can use majorities for fast replication in Fast Flexible Paxos but this will not be able to tolerate any failures as it requires that L=N if N is odd.
Our paper on Fast Flexible Paxos describes exactly how we calculated these equations. The paper also includes a proof of Fast Flexible Paxos, a formal specification of Fast Flexible Paxos written in TLA+ and a prototype using Paxi.
State machine replication is a powerful primitive for distributed systems, which has the power to provide the strongest possible consistency guarantees even in the face of message delays and failures. However, the performance limitations of state machine replication have long limited its adoption. I believe that Fast Flexible Paxos is the first step towards building more performant state machine replication protocols which can support fast replication, thus addressing the leader bottleneck, without requiring most servers to participate in replication.
[1] Strictly speaking, Zookeeper uses atomic broadcast and primary backup replication but the same high-level ideas apply to both.
[2] ¾ is only required to tolerate the same number of failures as Paxos with majorities.
[3] There is another issue with fast replication which is that conflicts can occur when multiple servers try to replicate different operations at the same time. Subsequent protocols like Generalized Paxos and Egalitarian Paxos mitigate this.