This article is brief overview of how middleboxes interact with DNS traffic. In particular I’m interested in finding out the answers to the following: Will middleboxes drop/modify DNS traffic and what is the purpose of this: stopping abuse, security, buggy implementations, advertising or censorship? Therefore does using your own stub resolver and recursive nameserver free you from the above issues? Do DNS recursive nameservers with caching respect the TTL? And ultimately how does the all this affect the deploy of DNS extensions such as DNSSEC, DNSCurve, DynDNS, EDNS?
My particular interest in DNS is how will research projects for naming edge network devices (e.g. HIP, UIA, UIP, MobilityFirst, CoDoNS, FERN) actually fair in the wild and is using or extending DNS a way around such issues. The title of this article is play on the title of the paper describing Delegation-Oriented Architecture.
Applications & Stub Resolvers
Stub resolver are in essence the clients to the Domain Name System (DNS), they sit between applications and DNS, usually ran locally by the OS and interfaced with by gethostbyname. The stub resolver is responsible for forming and parsing DNS packets for the application, offering a simple API to application for resolving domain names into IP address. The simplicity of this API is also its downfail, for example, gethostbyname has few error codes compared to DNS’s RCODEs. Proponents of DNSSEC hope that web browsers will present DNS validation failures to users in the same way that TLS failures are presented. At the moment however, for many stub resolvers the only possible error codes (often called h_errno) are HOST_NOT_FOUND, TRY_AGAIN, NO_RECOVERY and NO_ADDRESS. The application may not ever get this much information depending on the language API, such as Unix.gethostbyname in OCaml’s standard library.
A common linux default is to request AAAA records as well as A records even if the host doesn’t have a IPv6 address. Kreibich et al found that 13% of all sessions requested AAAA records: 42% of linux session requested AAAA records, compared to 10% of non-linux sessions, backing up this theory.
Some stub resolvers and client applications cache DNS responses, interestingly some do not respect TTLs. For example, the default cache time for ncsd (enabled by default on some linux distros) is 15 mins regardless of TTL, whereas internet explorer caches all records for 30 mins. It is important the caches respect short TTLs as they are increasingly utilised by content distribution networks and dynamic DNS. A quick check on my own browser (go to chrome://net-internals/#dns in chorme) shows that the browser cache contains 73 A/AAAA active records and 263 expired records.
Weaver et al. and Kreibich et al. studied how middleboxes interact with DNS traffic using the Netalyzr tool. Weaver et al. concluded that application wishing to use non-standard resource records (RRs) including TXT resources or DNSSEC should use their own DNS resolver and bypass the stub resolver provided by the host. It is often not possible for an application to overwrite the stub resolver’s choice of DNS resolver, which is normally a DNS resolver at the gateway, with a host of problems (see next section). The study also concluded that host stub resolvers often lack failovers (e.g. trying requests over TCP) to common issues such as: the gateway resolver not supporting the full DNS protocol, the gateway resolver cannot be trusted, the gateway resolver may be slow and the network gateway/middleboxes may filter UDP traffic.
In-Gateway Resolvers
The gateway resolver is a common (but not necessary) stage in DNS resolution (there may also be multiple stages of gateway resolvers). The stub resolver running on local host will usually forward the DNS query to the resolver(s) whos address it was given by DHCP lease when connecting to the local router. This address is normally a DNS resolver running at the gateway (at the .1 or .254 address in the local subnet e.g. 192.168.1.x) . I say “usually” as this can be overwritten, for example some people instead opt to use a public DNS server such as Google’s or OpenDNS, or run their own resolver, this is of course rare. Furthermore, not all gateways run DNS resolvers, in this case they typically refer hosts straight to the ISPs resolvers. Gateway resolvers have the advantage that they can enable the local resolution of domain such as .local or domain name for router adminisation (e.g. www.routerlogin.net for Netgear devices).
Weaver et al. tested the whether in-gateway resolvers correctly processed various DNS queries, they found that following: AAAA lookup (96%), TXT RRs (92%), unknown RRs (91%) and EDNS0 (91%). They also found that a significant number of in-gateway resolver are externally usable, opening the gateway to DoS attacks.
ISPs (& Other) Resolvers
The ISP’s resolver is a common (but not necessary) stage in DNS resolution (there many also be multiple stages of ISP resolvers). The ISP resolver is often the resolver responsible for begin to the actual resolution instead of just forwarding/proxying queries.
Despite there widespread deployment and dedicated management, these resolvers are not without there problems. Weaver et al found that 4% of sessions did not implement source port randomisation, only 55% of sessions exhibit EDNS0 usage, 4% of sessions implemented 0x20 whilst 94% propagate capitalisation unmodified. Kreibich et al found that 49% of sessions used DNSSEC enabled resolvers.
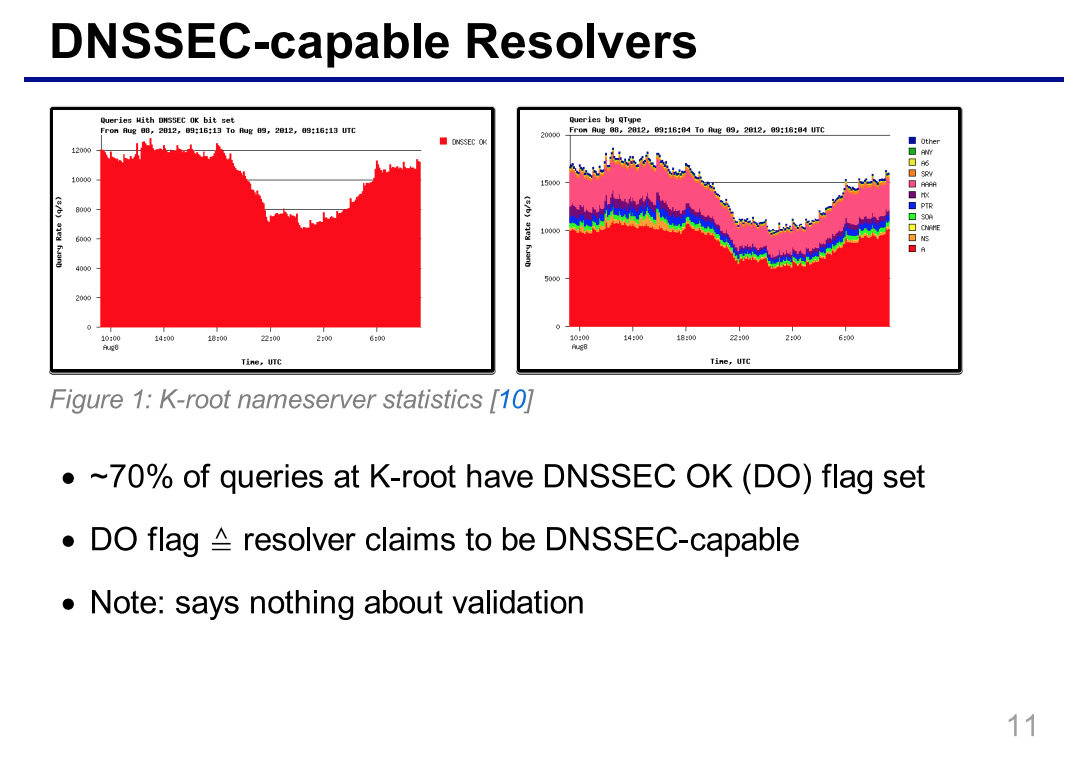
DNSSEC capable resolvers by Matthäus Wander
NXDOMAIN wildcarding is where resolvers replaces responses with the NXDOMAIN error (for example, when a user mistypes a domain) with valid DNS responses point to another site, often with advertising. Weaver et al observed this in 24% of the sessions surveyed. This should only be done on queries from web browsers, though this is not always the case. This may also interact with web browsers who treat NXDOMAIN errors specifically, e.g. if the query fails due to NXDOMAIN, then suggest some likely alternatives. Worryingly, Weaver et al also observed a few cases of SERVFAIL wildcarding, IPv4 addresses in responses where IPv6 only was requested and ignoring additional answer RRs. Some resolvers redirect queries for some search engine, whilst other have malware to inject adverting. Kreibich et al found that essentially all resolver respected a 0 and 1 second TTL.
Another interesting area is the treatment of RRs from the Authority and Additional RR sets. For example, glue records are A RRs in the Additional section added to an answer with NS RRs which put the name servers under the domain they control, without these additional RR’s we would have a circular dependency. Kreibich et al found that 61% of sessions accept glue records when the glue records refer to authoritative nameservers, 25% accept A records corresponding to CNAMEs contained in the reply and 21% of sessions accepting any glue records present in the Additional field, and those only doing so for records for subdomains of the authoritative server.
Other ISP controlled middleboxes
It is clear that resolvers (stub, in-gateway and ISP/Public) do not reliability handle all DNS traffic and all its extensions. Users could opt to run there own resolver and stub resolvers, would this mean that their traffic be free from modification by middleboxes? Of course not.
ISPs have been know to highjack traffic to port 53 to their own DNS resolvers or simply drop it, blocking use of third party DNS resolvers. Some public resolvers support alternative ports (e.g. OpenDNS supports port 5353), but this can be difficult to configure as its cannot be easily expressed in /etc/resolv.conf. There is some evidence of gateways provided by ISPs, redirecting traffic to port 53 to the ISP’s DNS resolvers
TLDs and Root Servers
The root DNS server (or actually the 504 servers, 13 addresses) is the heart of the DNS. The root has supported DNSSEC since 2010, will not support DNSCurve. Likewise many of the TLD’s support DNSSEC and will not support DNSCurve. On the whole, these seems to fairly well managed and free of major issues.











