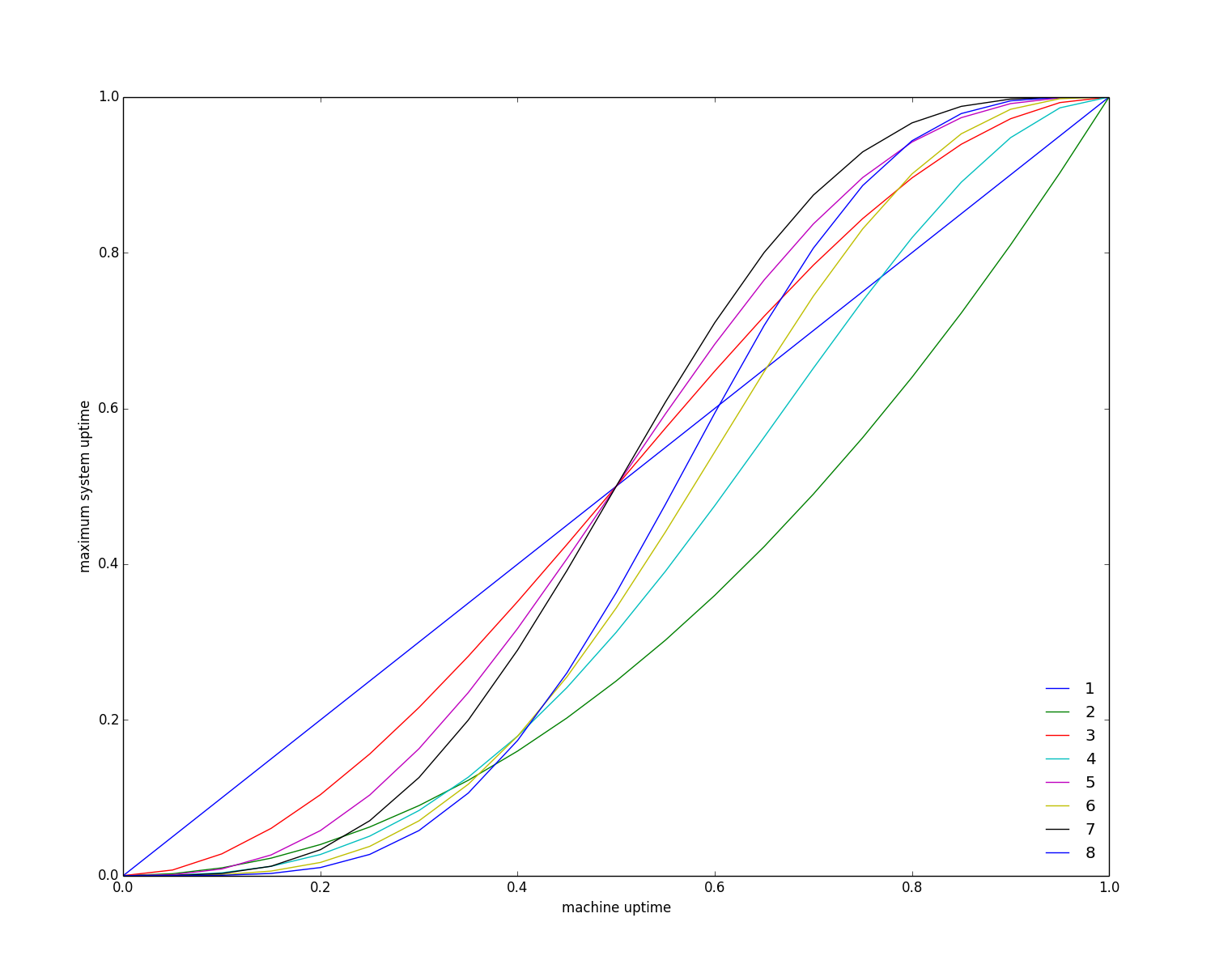
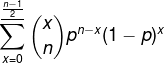This is the first post in the “Chronicle of Coracle” series to document daily life using OCaml for systems programming.
Today, I’ll be adding protocol specific parameters to Coracle, this mostly involves working with the Yojson and Cmdliner libraries. Once completed, Coracle will be able to accept JSON files like:
{"nodes": 50,"loss": 0.0, "termination":1000, "consensus": {"protocol":"raft","timeout":300}}
Stage 1 – Protocol selection
The value associated with “protocol” key determines how which consensus protocol is ran by the simulator. Though this value seems like an unusual starting place, the simulator is a functor over the specific consensus implementation, thus we much choose our consensus implementation first before anything else. We extract the protocol name as follows:
let get_protocol filename = try (
Safe.from_file filename
|> function `Assoc config -> config
|> List.assoc "consensus"
|> function `Assoc proto -> proto
|> List.assoc "protocol"
|> function `String str -> str
|> function "raft" -> `Raft | "vrr" -> `VRR
) with _ -> raise JSON_parsing_failure
This approach gets the job done but could be improved using some kinda option/error monad instead of exceptions and providing more detailed information to the user on why the JSON parsing failed. We added various other JSON parsing functions, all of follow a similar pattern one above. We needed to do a bit more work to get these to type correctly, as described in Stage 3.
Stage 2 – The dummy module
Based on the protocol given in the JSON configuration file, we apply a different consensus module to the simulation functor. At the moment we only have support for the Raft protocol, so here is the type sig for consensus modules and a new dummy consensus module we can use in testing.
module type CONSENSUS = sig
type state
type config
val parse_config: json -> config
val init: id list -> config -> state
val add_peers: id list -> state -> state
val state_to_string: state -> string
type msg
val msg_serialize: msg -> string
val msg_deserialize: string -> msg
val msg_to_string: msg -> string
val eval: msg input -> state -> state option * msg output list
end
And the dummy module:
open Common
open Io
open Yojson.Safe
type state = {
peers: id list;
counter: int;
say_hello_to: int;
}
type config = int
let parse_config json =
function `Assoc config -> config
|> List.assoc "id"
|> function `Int i -> i
let init peers id = {
peers; counter=0; say_hello_to=id}
let add_peers new_peers s =
{s with peers=s.peers@new_peers}
let state_to_string s = string_of_int s.counter
type msg = Hello | HelloBack
let msg_to_string = function
| Hello -> "hello"
| HelloBack -> "hello back"
let msg_serialize = msg_to_string
let msg_deserialize = function
| "hello" -> Hello
| "hello back" -> HelloBack
let eval event state =
match event with
| PacketArrival (id,Hello) ->
(None, [PacketDispatch (id, HelloBack)])
| PacketArrival (_,HelloBack) ->
(Some {state with counter=state.counter +1}, [])
| Startup _ ->
(None, [PacketDispatch (state.say_hello_to, Hello)])
This was just a quick hack to test that the simulator will generalise over consensus implementations.
Stage 3 – Using mli files to generalise polymorphic variants
Yojson uses polymorphic variants for describing the structure of JSON files. Polymorphic variants (the ones which start with the backtick) can be declared on the fly and don’t need type definitions beforehand. Initially, we got type errors like this for many of our JSON parsing functions:
Error: Signature mismatch:
...
Values do not match:
val parse_config :
[< `Assoc of (string * [> `Int of int ]) list ] -> config
is not included in
val parse_config : Yojson.Safe.json -> config
These issues where quickly address by adding mli files or :json type annotations
Stage 4 – Knowing when to give up
The simulation command line interface (without using config files) had become exponentially more complex, both in terms of implementation and usage. As of this PR, we on longer support command line simulation without the use of a config file. In hindsight, its unlikely that many would use this interface due to the unmanageable number of parameters (around 2 dozen for ocaml-raft)
Stage 5 – Protocol Selector
Now that we are able to parse the JSON config files and we have multiple protocols to choice between, we can write our protocol selector:
let protocol_selector config_file trace output_file no_sanity =
match Json_handler.get_protocol config_file with
| `Raft ->
let module R = Simulator.Simulate(Raft) in
R.start config_file trace output_file no_sanity
| `Dummy ->
let module R = Simulator.Simulate(Dummy) in
R.start config_file trace output_file no_sanity
Since we only have two protocols to choose between, I’ve opted to duplicate the R.start line instead of using first class modules (fcm) as fcm requires packing and unpacking. Interestingly, I can’t directly call start from Simulator.Simulate(Raft), you need to assign it to an intermediate module in between. I’m not sure why this is case.
Conclusion
You can now pass protocol specific parameter to Coracle using JSON configuration files. This will be live on the demo server by tonight. Tomorrow, we will look at adding clients to the simulator.